Introduction to Agentic Mesh and Its Challenges
What is an agentic mesh?
In recent years the term agentic mesh has moved from academic papers to production‑grade systems. At its core, an agentic mesh is a network of autonomous, purpose‑built AI agents that collaborate to solve complex problems. Each agent encapsulates a single capability—such as summarisation, entity extraction, or sentiment analysis—and communicates with its peers through well‑defined protocols. The mesh topology allows the system to dynamically route data, parallelise work, and recover from failures without a single point of control.
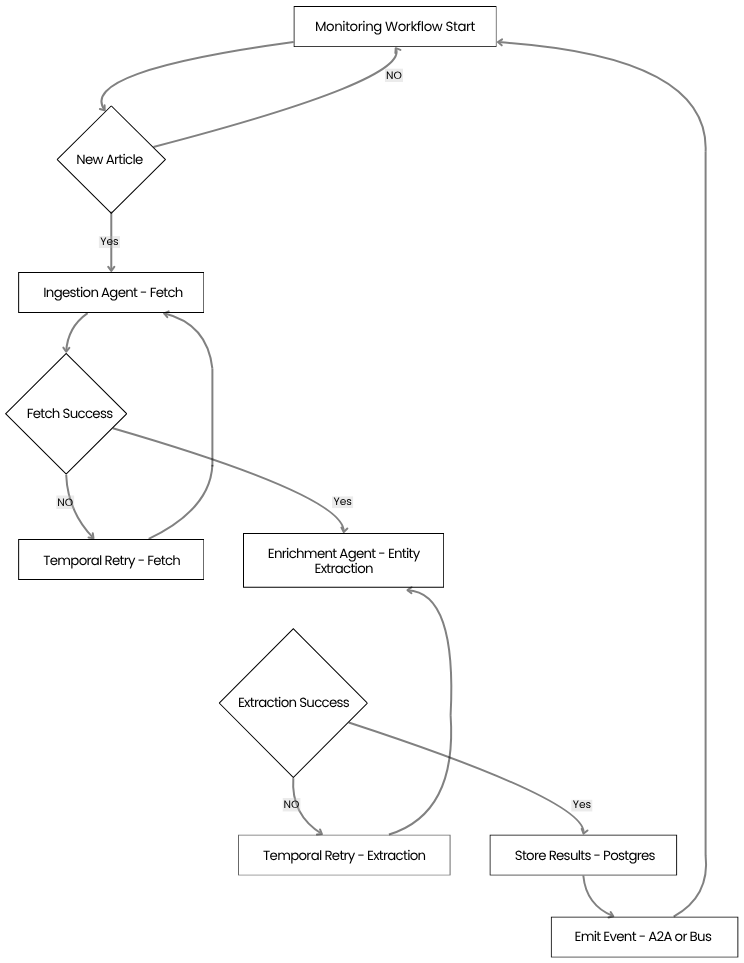
Imagine a newsroom that receives a breaking story, enriches it with background context, extracts key entities, and then pushes personalised alerts to multiple platforms. Instead of a monolithic pipeline that runs every step sequentially, the mesh spins up the exact agents required for that story, lets them exchange messages, and discards them when the job is finished. This on‑demand, plug‑and‑play approach is what makes modern news intelligence both fast and cost‑effective.
Challenges with monolithic AI pipelines
Traditional AI pipelines are often built as long, linear chains of micro‑services or as a single heavyweight application. While straightforward to prototype, they suffer from several drawbacks:
- Scalability bottlenecks – A single service becomes the limiting factor when traffic spikes, and horizontal scaling is hard because the whole pipeline must be duplicated.
- Tight coupling – Changing one component (e.g., swapping a summarisation model) forces downstream services to be retested, increasing the risk of regression.
- Limited fault tolerance – If any step crashes, the entire request fails, requiring expensive retry logic and manual intervention.
- Resource waste – Every request must pass through every stage, even if only a subset of capabilities is needed, leading to unnecessary compute consumption.
- Lack of temporal awareness – Traditional pipelines are typically batch-oriented and operate within fixed execution windows. They lack native support for:
- real-time event handling
- long-running workflows
- stateful retries and resumability
As a result, they struggle to react to evolving signals (e.g., breaking news, rapidly changing narratives) in a timely and reliable manner. Any attempt to add durability or real-time responsiveness often requires custom scheduling, retry logic, and state management – leading to increased system complexity.
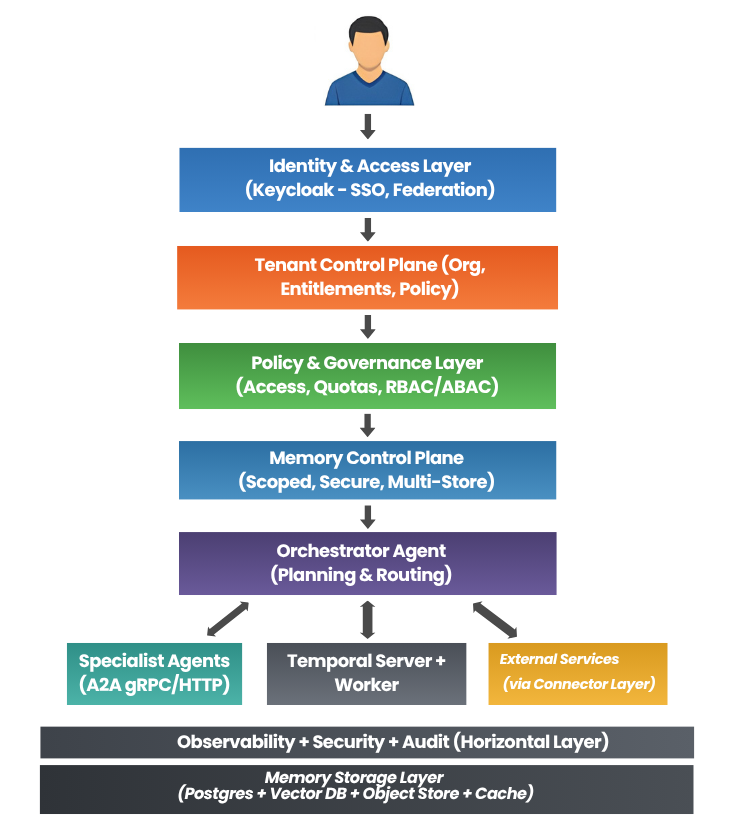
These pain points push organisations toward a more modular, resilient architecture – precisely what an agentic mesh promises. However, moving from monolithic pipelines to a distributed mesh introduces its own set of engineering challenges: protocol design, state management, orchestration, and observability become critical concerns.
So we built an agent-first mesh architecture where:
- Orchestrator decides
- Specialists execute
- A2A connects everything
- Temporal handles durability
- OpenAI Agents SDK powers reasoning
This is not theoretical. This is what we actually built.